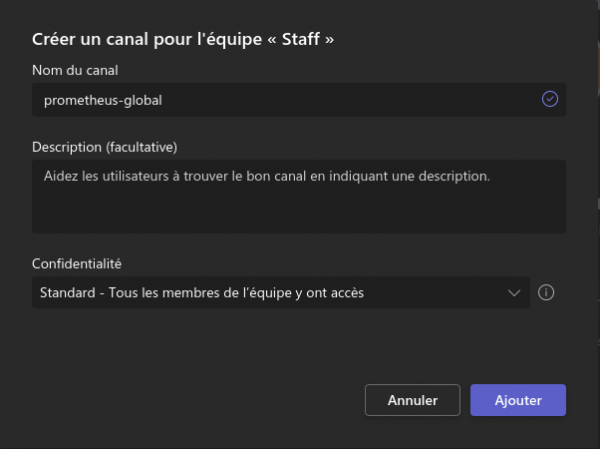
En face de votre équipe, sur les trois petits points vous trouverez l’option ajout un canal :

Vous pouvez ensuite lui choisir un nom et définir les accès :

Appuyez ensuite sur les trois points, mais en face de votre canal ce coup-ci afin de trouver l’option connecteurs :

Trouvez “webhook” et appuyez sur Configurer

Définissez un nom et appuyez sur Creer

Notez bien l’URL de votre webhook, car nous allons devoir l’indiquer à l’alertmanager de prometheus !
Vous pouvez créer plusieurs canaux ou plusieurs équipes pour séparer les flux de notifications, par exemple si vous avez deux équipes qui travaillent sur des clusters swarm différents, on pourra particulariser les alertes de chacun vers son équipe respective !
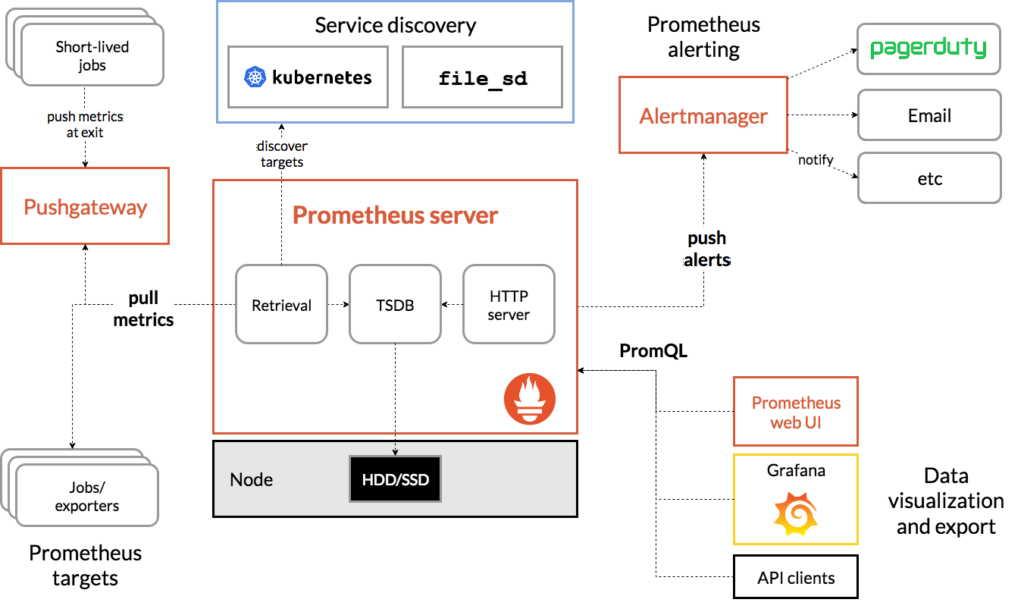
Ajout d’un conteneur pour faire l’interface entre l’alertmanager et teams
Nous allons utiliser le projet prometheus-msteams. Il faut l’ajouter en temps que service dans la stack avec le bloc suivant :
teams-forwarder: image: quay.io/prometheusmsteams/prometheus-msteams ports: - 2000:2000 networks: - metrics
Pas de configuration nécessaire.
Test de notre webhook
Si tout va bien, on a maintenant un container qui va écouter sur le port 2000. Il va envoyer les requêtes vers le webhook teams dans le bon format en fonction de ce que nous lui envoyons nous même en HTTP. Donc on peut essayer nous-même de construire une requête fictive et lui envoyer pour voir si elle parvient bien jusqu’à notre teams !
Ecrivez le fichier json suivant :
{
"version": "4",
"groupKey": "{}:{alertname=\"high_memory_load\"}",
"status": "firing",
"receiver": "teams_proxy",
"groupLabels": {
"alertname": "high_memory_load"
},
"commonLabels": {
"alertname": "high_memory_load",
"monitor": "master",
"severity": "warning"
},
"commonAnnotations": {
"summary": "Server High Memory usage"
},
"externalURL": "http://docker.for.mac.host.internal:9093",
"alerts": [
{
"labels": {
"alertname": "high_memory_load",
"instance": "10.80.40.11:9100",
"job": "docker_nodes",
"monitor": "master",
"severity": "warning"
},
"annotations": {
"description": "10.80.40.11 reported high memory usage with 23.28%.",
"summary": "Server High Memory usage"
},
"startsAt": "2018-03-07T06:33:21.873077559-05:00",
"endsAt": "0001-01-01T00:00:00Z"
}
]
}On peut ensuite tester avec curl en faisant un requête POST sur l’url du container suivie de celle de votre webhook comme ceci :
curl -X POST -d @/chemin/vers/le/file/json http://ip_d'un_node_de_votre_swarm:2000/_dynamicwebhook/url_de_votre_webhook_donnée_par_teams'
On passe en fait l’url de votre webhook dans le path de la requête HTTP, d’où le nom “dynamicwebhook” devant… Ça nous évite de configurer prometheus-msteams. Vous devriez recevoir une carte dans teams, si ce n’est pas le cas, merci de contacter votre administrateur système.
Modification de la configuration du serveur prometheus
Ajout du service alertmanager
Il nous suffit de déclarer un container docker de plus dans la stack avec le bout de yaml suivant :
alert-manager: image: quay.io/prometheus/alertmanager command: - --config.file=/etc/prometheus/alertmanager.yml ports: - 9093:9093 networks: - metrics configs: - source: geco-alertmanager target: /etc/prometheus/alertmanager.yml
Rien de particulier ici, on ajoute juste un container, avec un port et on lui passe une config. C’est sur cette dernière que nous allons nous attarder.
global: smtp_smarthost: 'xxx.geco-it.net:587' smtp_from: 'prometheus@labo.geco-it.net' # Définition des params pour l'envoie de mail, je ne l'utilise pas mais ils sont la pour example. smtp_auth_username: 'xxx@geco-it.fr' smtp_auth_password: 'xxx' # A partir de la on défini la logique de distribution des alertes, la clause "route" defini le chemin par defaut d'une alerte, et dessous on pourra # déclarer des "routes", notez bien le "S", enfant qui seront des bifurcation par rapport au chemin de base. # Je m'explique : ci dessous notre route de base, on envoie a geco-team qui est un recepteur defini plus bas. Les directives group_* permettent de grouper les alertes par paquets. Et le repeat sert # a renvoyer une alerte toutes les 3h tant qu'elle n'est pas traitée ! route: receiver: 'geco-team' group_by: ['alertname', 'cluster'] group_wait: 30s group_interval: 5m repeat_interval: 3h # Ici je définis une route alternative qui envoie les alertes sur un autre récepteur. Pour décider quelle alerte va emprunter quelle route, on utilise la directive "match" qui va permettre de sélectionner les alertes par labels. Dans mon cas, je redirige les alertes qui possèdent la valeur critical pour le label severity vers le recepteur geco-hugo. # Pour rappel, dans prometheus, chaque métriques se voit associer un ensemble de label qui sont simplement des groupes clé / valeur. Certaines sont induites par défaut, d'autre peuvent être ajoutées par votre config, à votre guise ! routes: - match: severity: critical receiver: geco-hugo # Ici on trouve le bloc des règles d'inhibition qui permettent de désactiver certaines alertes en fonction de certains critères. La règle désactive les alertes qui matchent avec le target, si la source matche. Dans l'exemple ci-dessus on désactive les warnings, si on trouve une alerte avec le même nom mais en critique. Ça évite d'en avoir deux pour un même problème. inhibit_rules: - source_matchers: - severity="critical" target_matchers: - severity="warning" equal: ['alertname'] receivers: # Ici on déclare les "récepteurs" des alertes, ça sera votre ou vos canal / canaux teams, voir slack ou autre. - name: 'geco-team' webhook_configs: - send_resolved: true # Send resolved permet d'envoyer ou nom une notification sur le retour à la normale d'une alerte. url: 'http://teams-forwarder:2000/_dynamicwebhook/' - name: 'geco-hugo' webhook_configs: - send_resolved: true url: 'http://teams-forwarder:2000/_dynamicwebhook/'
Plus de détails sur les routes, et la config de l’atermanager possible ici
Il nous reste à modifier la configuration du prometheus lui-même pour deux raisons :
- Déclarer le container qui fait tourner l’alertmanager, pour que prometheus lui envoie les dites alertes
- Déclarer un fichier “rules” dans lequel on définira justement nos alertes !
On ajoute le bloc suivant :
alerting: alertmanagers: - static_configs: - targets: ['alert-manager:9093'] rule_files: - /etc/prometheus/alerts.rules
Ajout de rules d’alerting
L’ajout des rules se fait donc dans le fichier séparé que l’on a renseigné juste avant. Les rules prometheus ont le format suivant :
- alert: Le nom de votre alerte expr: expression qui va servir à définir une valeur et son état critique ou non for: la période pendant laquelle la condition ci-dessus devra être remplie pour enclencher l'alerte labels: votre_label: la valeur que vous voulez annotations: summary: Un résumé écrit de l'alerte pour pouvoir donner plus d'infos que dans le nom. Vous pouvez utiliser des valeurs de label dans ce résumé, nous allons voir comment !
Pour construire vos alertes, le mieux est de tester votre expression dans la webui de prometheus, nous allons construire ensemble une règle pour alerter sur une utilisation disque importante. Admettons que nous voulions notifier quand il ne reste que 5Go d’espace libre sur le disque d’une machine. Nous pouvons utiliser l’expression suivant et la tester dans la webui:
node_filesystem_free_bytes / (1024*1024*1024) <= on fait la division pour convertir en Go
Vous obtenez donc un graph qui valide votre expression, notez aussi les labels que prometheus associe à votre requête car vous allez pouvoir les utiliser et agrémenter votre alerte !

On trouve ici par exemple les labels “instance” pour la machine concernée et “mountpoint” pour le point de montage concerné, deux infos très utiles que l’on va utiliser.
Créons donc notre première règle avec notre expression précédemment testée :
groups: - name: example-alerting rules: - alert: TooMuchDiskUsage expr: node_filesystem_free_bytes / (1024*1024*1024) < 5 for: 1m labels: severity: warning annotations: summary: Filesystem mounted on {{ $labels.mountpoint }} on {{ $labels.instance }} has less than 5Go free #Les valeurs entre {{}} vont automatiquement être remplacée par celles des labels.
Si vous cliquez sur la partie alerte de l’interface, vous devriez retrouver votre alerte :

Cassons notre machine pour la science…
On va se connecter en shell sur un des workers docker et créer un énorme file avec la commande dd
admin@docker-worker1:~$ df -h Filesystem Size Used Avail Use% Mounted on udev 991M 0 991M 0% /dev tmpfs 200M 21M 180M 11% /run /dev/sda1 20G 11G 8,2G 57% / tmpfs 999M 0 999M 0% /dev/shm tmpfs 5,0M 0 5,0M 0% /run/lock tmpfs 999M 0 999M 0% /sys/fs/cgroup admin@docker-worker1:~$ echo $((1024*6)) 6144 admin@docker-worker1:~$ sudo dd if=/dev/zero of=/opt/bigfile bs=1M count=6144 6144+0 records in 6144+0 records out 6442450944 bytes (6,4 GB, 6,0 GiB) copied, 53,7303 s, 120 MB/s admin@docker-worker1:~$ df -h Filesystem Size Used Avail Use% Mounted on udev 991M 0 991M 0% /dev tmpfs 200M 21M 180M 11% /run /dev/sda1 20G 17G 2,2G 89% / tmpfs 999M 0 999M 0% /dev/shm tmpfs 5,0M 0 5,0M 0% /run/lock tmpfs 999M 0 999M 0% /sys/fs/cgroup
On constate qu’il nous reste 2.2go de libre donc notre alerte devrait se lancer vu qu’on est sous les 5Go. Visitons l’interface web pour confirmer :

L’alerte est en pending, cela veut dire que prometheus va attendre une minute avec de confirmer la situation. Dans le cas de la place disque, ce n’est pas forcément pertinent, mais sur l’utilisation du CPU par exemple, ça permet d’effacer les faux positifs liés à un pic de charge de courte durée. Le temps que j’écrive ces mots, l’alerte a du passer en “firing” :

Quand on atteint la minute, l’alerte est envoyée à l’alertmanager qui se chargera de la dispatcher vers la ou les personne(s) concernée(s). Si le seuil repasse a un niveau normal avant la minute d’attente, rien n’est fait. On peut d’ailleurs bien vérifier sur la webui de l’alertmanager lui-même sur le port 9093 :

Et finalement la carte doit se trouver dans notre teams :

Conclusion
Comme dans le cadre de l’article précédent sur prometheus, je n’ai fait qu’effleurer les possibilités offertes par le produit. Le but, au-delà de faire des alertes pour chacun de vos services importants, est d’optimiser ces dernières. Toute la puissance de prometheus réside dans le fait de pouvoir faire des alertes fines, sur des objets précis et de pouvoir les dispatcher entre différentes équipes ou différents canaux ( SMS, mail, slack, etc… ). Il faudra aussi évidemment jouer sur le seuil et la close “for” pour écarter tous les soucis non-critiques dans le but de recevoir seulement des notifications utiles. Le but des alertes en supervision, c’est de ne jamais en recevoir. Plus on en reçoit, plus on a tendance à l’ignorer, alors que si elles sont ponctuelles, elles sont beaucoup plus marquantes.